作为一个常识,当我们在处理一些长连接的业务时,客户端往往需要负责断线重连。比如,在我们的一个系统中,是这么处理 RabbitMQ 的断线重连的:
func (c *Consumer) Start() error {
if err := c.Run(); err != nil {
return err
}
go c.ReConnect()
return nil
}
func (c *Consumer) Run() error {
var err error
if c.conn, err = amqp.Dial(c.addr); err != nil {
return err
}
if c.channel, err = c.conn.Channel(); err != nil {
c.conn.Close()
return err
}
if _, err = c.channel.QueueDeclare(
c.queue, // name
false, // durable
c.autoDelete, // delete when usused
false, // exclusive
false, // no-wait
nil, // arguments
); err != nil {
c.channel.Close()
c.conn.Close()
return err
}
var delivery <-chan amqp.Delivery
if delivery, err = c.channel.Consume(
c.queue, // queue
c.consumerTag, // consumer
false, // auto-ack
false, // exclusive
false, // no-local
false, // no-wait
nil, // args
); err != nil {
c.channel.Close()
c.conn.Close()
return err
}
go c.Handle(delivery)
c.connNotify = c.conn.NotifyClose(make(chan *amqp.Error))
return err
}
func (c *Consumer) ReConnect() {
for {
select {
case err := <-c.connNotify:
if err != nil {
log.Error("rabbitmq consumer - connection NotifyClose: ", err)
}
case <-c.quit:
return
}
// backstop
if !c.conn.IsClosed() {
// close message delivery
if err := c.channel.Cancel(c.consumerTag, true); err != nil {
log.Error("rabbitmq consumer - channel cancel failed: ", err)
}
if err := c.conn.Close(); err != nil {
log.Error("rabbitmq consumer - channel cancel failed: ", err)
}
}
quit:
for {
select {
case <-c.quit:
return
default:
log.Error("rabbitmq consumer - reconnect")
if err := c.Run(); err != nil {
log.Error("rabbitmq consumer - failCheck: ", err)
// sleep 5s reconnect
time.Sleep(time.Second * 5)
continue
}
break quit
}
}
}
}
这段代码在多数情况下,会工作的很好,但是却埋了一个巨大的隐患。就是假如 RabbitMQ Server 并没有主动关闭连接,而仅仅是关闭了 channel,那么我们的断线重连就永远不会触发。因为根本就没有断线嘛,心跳也是正常的,自然 conn.NotifyClose 也不会触发 error 了。
那么问题来了,RabbitMQ Server 为什么会关闭 channel 呢?官方列出了几个原因:
- 406 PRECONDITION_FAILED
- 403 ACCESS_REFUSED
- 404 NOT_FOUND
- 405 RESOURCE_LOCKED
而我踩的这个坑,正是由于「重复 ACK」引起的 406 PRECONDITION_FAILED。在 AMQP 里用来确认消息的接口是 delivery.Ack(multiple bool),当 multiple=false 时,仅会确认当前的消息;而当 multiple=true 时,会确认该 channel 中小于当前 delivery tag 的所有未确认消息,主要用于批量确认,降低网络消耗。
举个例子:
func (c *Consumer) Handle(delivery <-chan amqp.Delivery) {
for d := range delivery {
if err := c.handler(delivery.Body); err == nil {
d.Ack(true)
} else {
// 重新入队,否则未确认的消息会持续占用内存
d.Reject(true)
}
}
}
如果 handler 就像上面一样,是个同步的实现,那么 d.Ack(false) 和 d.Ack(true) 没有任何区别。但是在我们的业务里,却是个异步的实现:
func (c *Consumer) Handle(delivery <-chan amqp.Delivery) {
for d := range delivery {
go func(delivery amqp.Delivery) {
if err := c.handler(delivery.Body); err == nil {
delivery.Ack(true)
} else {
// 重新入队,否则未确认的消息会持续占用内存
delivery.Reject(true)
}
}(d)
}
}
这就出问题了,比如现在有 10 条消息,它们都是并发处理的,如果第 10 条消息最先处理完毕,那么前 9 条消息都会被 delivery.Ack(true) 给确认掉。后续 9 条消息处理完毕时,再执行 delivery.Ack(true),显然就会导致消息重复确认。而在 AMQP 的 SPEC 中明确指出:
A message MUST not be acknowledged more than once. The receiving peer MUST validate that a non-zero delivery-tag refers to a delivered message, and raise a channel exception if this is not the case. …
所以当 RabbitMQ Server 收到重复确认时,便会触发 error 关闭 channel,但是并不会关闭连接。这时候服务也不会触发重连,就一直 stuck 在那里。
要解决这个问题,把 delivery.Ack(true) 改为 delivery.Ack(false) 即可。为了更加保险,索性我又监听了 channel 的 NotifyClose:
go c.Handle(delivery)
c.connNotify = c.conn.NotifyClose(make(chan *amqp.Error))
c.channelNotify = c.channel.NotifyClose(make(chan *amqp.Error))
return err
}
func (c *Consumer) ReConnect() {
for {
select {
case err := <-c.connNotify:
if err != nil {
log.Error("rabbitmq consumer - connection NotifyClose: ", err)
}
case err := <-c.channelNotify:
if err != nil {
log.Error("rabbitmq consumer - channel NotifyClose: ", err)
}
case <-c.quit:
return
}
这下似乎可以高枕无忧了吧,呵呵。。。
在测试环境跑了一阵子发现,服务虽然可以正常触发重连,但是老的连接却释放的很慢(10min+):
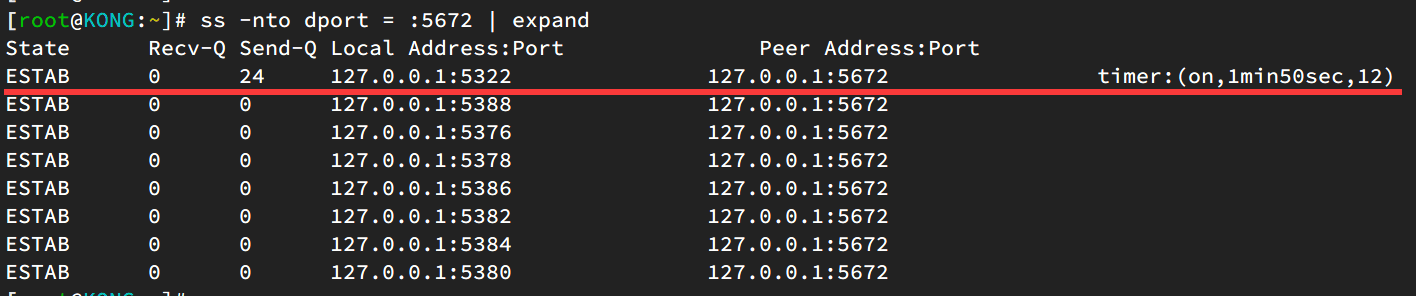
ss 观察到 rto 时间已经 backoff 到了 120s,明显是发生了重传。
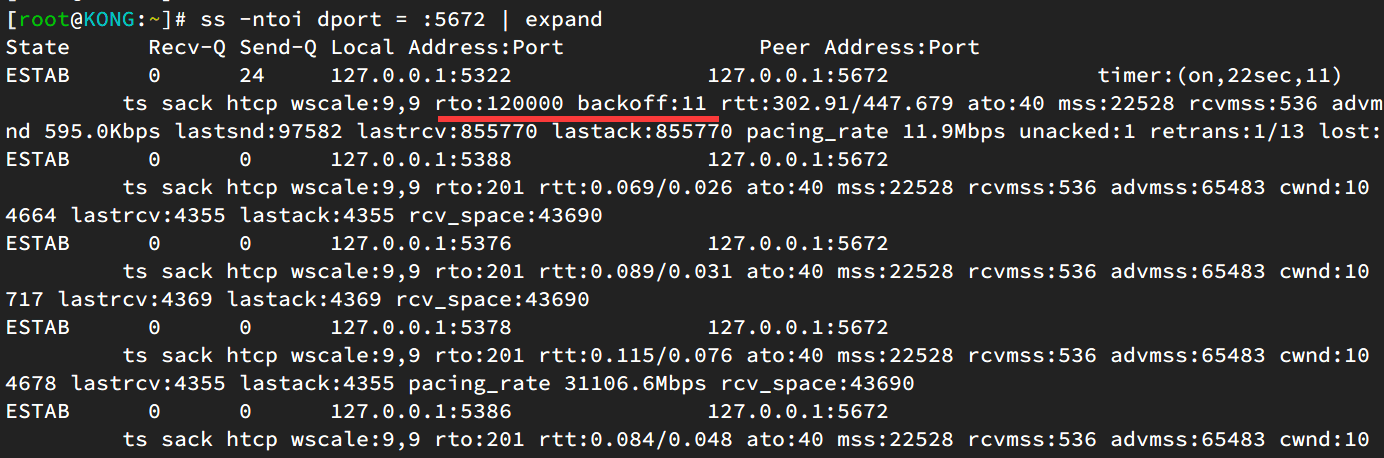
关键是连接状态居然还处于 ESTABLISHED,说明并不是 FIN 的重传。通过抓包分析,可以进一步确认是在重传心跳包,并且心跳包的长度是 8 个字节,而上面 ss 观察到 send 缓冲区有 24 个字节,恰好是 3 个心跳包的大小。
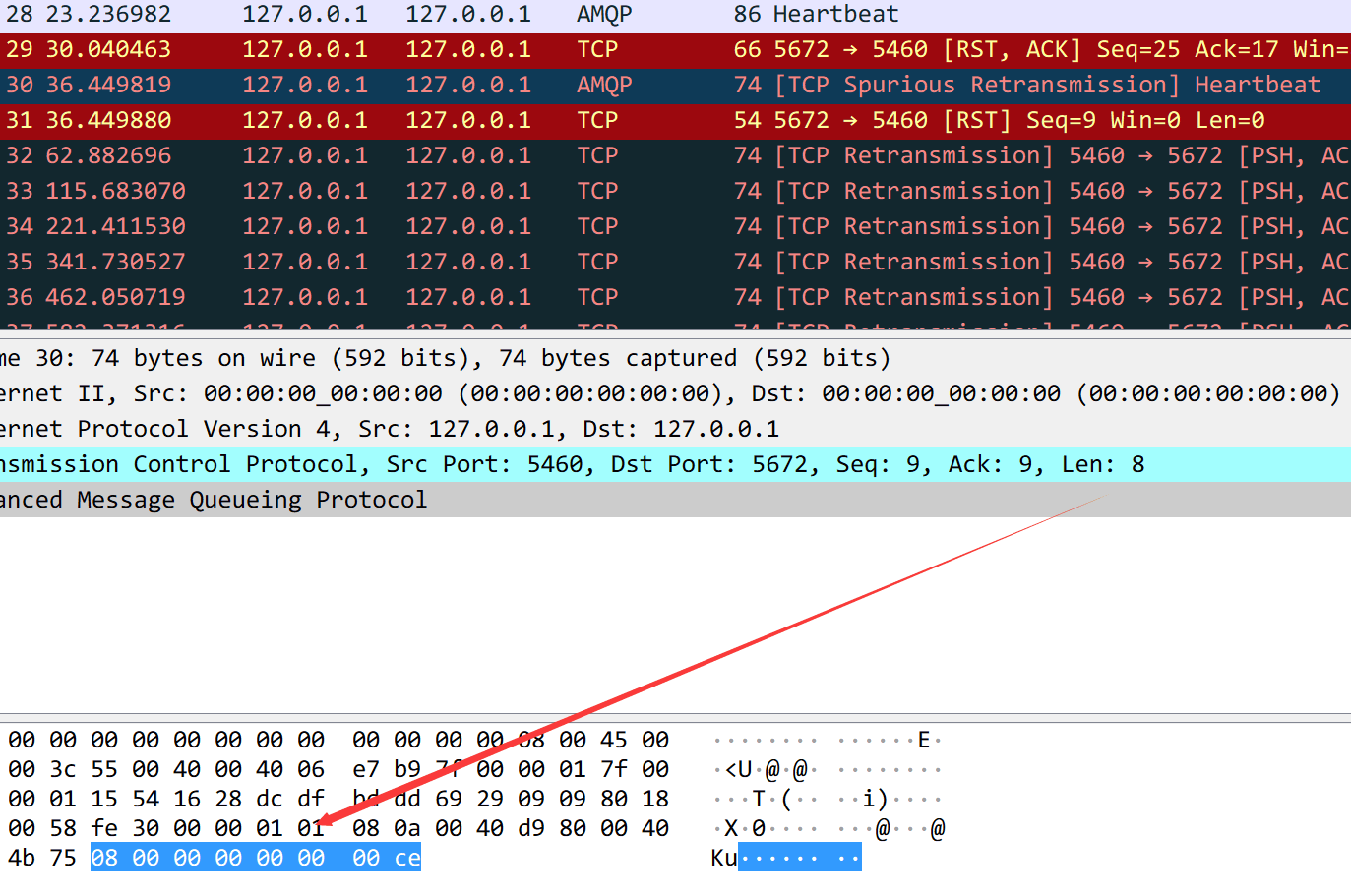
既然已经触发了重连,为什么还会重传心跳呢?即使重传,也应该是 FIN 啊,只能说明程序还没有走到 close() 那步,还没有发 FIN。带着这些疑问,继续追查 stack 信息,果然看到有一个 goroutine 卡在了 shutdown 的地方:
goroutine 45 [chan send]:
foo/vendor/github.com/streadway/amqp.(*Channel).shutdown.func1()
/root/gofourge/src/foo/vendor/github.com/streadway/amqp/channel.go:104 +0x10a
sync.(*Once).Do(0xc00025a000, 0xc000057d78)
/usr/local/go/src/sync/once.go:44 +0xb3
foo/vendor/github.com/streadway/amqp.(*Channel).shutdown(0xc00025a000, 0xc0000a3060)
/root/gofourge/src/foo/vendor/github.com/streadway/amqp/channel.go:93 +0x63
foo/vendor/github.com/streadway/amqp.(*Connection).shutdown.func1()
/root/gofourge/src/foo/vendor/github.com/streadway/amqp/connection.go:419 +0x1f8
sync.(*Once).Do(0xc00016b180, 0xc000057eb8)
/usr/local/go/src/sync/once.go:44 +0xb3
foo/vendor/github.com/streadway/amqp.(*Connection).shutdown(0xc00016b180, 0xc0000a3060)
/root/gofourge/src/foo/vendor/github.com/streadway/amqp/connection.go:389 +0x6c
foo/vendor/github.com/streadway/amqp.(*Connection).reader(0xc00016b180, 0xaea4e0, 0xc00000e160)
/root/gofourge/src/foo/vendor/github.com/streadway/amqp/connection.go:524 +0x196
created by foo/vendor/github.com/streadway/amqp.Open
/root/gofourge/src/foo/vendor/github.com/streadway/amqp/connection.go:233 +0x25f
通过进一步分析 AMQP 的源码,最后可以确认 shutdown 是阻塞在了 channel 的关闭上(顺便也能看到确实还没有触发连接的 close()):
for _, ch := range c.channels {
ch.shutdown(err)
}
c.conn.Close()
至此,问题就已经非常清晰了:当发生网络异常时,`<-c.connNotify` 首先被触发,然后重连成功;异常的连接会自己触发 `shutdown()`,但是我注册的 channelNotify 并没有缓冲,所以异常的连接一直阻塞在了 channel 的关闭中,也没有触发 FIN。而这时候异常连接的心跳还在发送,但是并没有收到回复或 RST,所以一直在重传,直到系统限制被强制关闭。
你可能会有疑问:既然连接已经挂掉了,心跳会收到 RST 的啊。是的,没错。这就要介绍下我的网络环境了:
server --> firewall --> rabbitmq-server
导致异常的是,firewall 和 rabbitmq-server 之间 i/o timeout,既然是长连接,server 端自然也会 i/o timeout并成功重连。接着 server 端的异常连接继续给 rabbitmq-server 发心跳,firewall 收到请求后,发现没有这个连接的信息(只有新连接的),注意这时候 firewall 不发送 RST,也不回复,而是自己默默的丢弃了!!! 接下来便是心跳的重传。实在是太坑了。
也许有小伙伴会说,我们没有 firewall,所以不会存在这个问题。too young, too naive.
没有 firewall 的话,只是不会观察到重传这个现象,让问题更加隐蔽了而已。实际上老的连接依然并没有被 GC 掉,还是阻塞在 channel 的关闭中。只是你无法通过 `ss` 观察到而已,通过 goroutine stack 就能看到泄露了。
问题归根结底是因为 conn 和 channel 的 NotifyClose 没有被拉干净,导致死掉的连接被阻塞在 NotifyClose 上,一直没有被 GC 掉。所以在 reconnect 一定要切记,拉取干净 NotifyClose:
select {
case err := <-c.connNotify:
if err != nil {
log.Error("rabbitmq consumer - connection NotifyClose: ", err)
}
case err := <-c.channelNotify:
if err != nil {
log.Error("rabbitmq consumer - channel NotifyClose: ", err)
}
case <-c.quit:
return
}
// backstop
if !c.conn.IsClosed() {
// 关闭 SubMsg message delivery
if err := c.channel.Cancel(c.consumerTag, true); err != nil {
log.Error("rabbitmq consumer - channel cancel failed: ", err)
}
if err := c.conn.Close(); err != nil {
log.Error("rabbitmq consumer - channel cancel failed: ", err)
}
}
// IMPORTANT: 必须清空 Notify,否则死连接不会释放
for err := range c.channelNotify {
println(err)
}
for err := range c.connNotify {
println(err)
}
其实对于 AMQP 的重连,社区已经讨论了很多。AMQP 的主要开发者认为重连是业务的事情,所以不愿意在 AMQP 底层中加入更多自动重连的逻辑。但是从系统设计的角度来看,到底是要业务优先,还是功能优先,似乎一直都是个问题。