Any race is a bug
我在接手其他同事的 golang 项目时,一般都会习惯性的做一个竞态检测。有时总会得到一些“惊喜”,比如像下面这段代码:
package main
import (
"fmt"
"runtime"
"time"
)
var i = 0
func main() {
runtime.GOMAXPROCS(2)
go func() {
for {
fmt.Println("i is", i)
time.Sleep(time.Second)
}
}()
for {
i += 1
}
}
当通过 go run -race cmd.go 执行时,可以看到有明显的竞态出现:
==================
WARNING: DATA RACE
Read at 0x0000005e4600 by goroutine 6:
main.main.func1()
/root/gofourge/src/lab/cmd.go:15 +0x63
Previous write at 0x0000005e4600 by main goroutine:
main.main()
/root/gofourge/src/lab/cmd.go:20 +0x7b
Goroutine 6 (running) created at:
main.main()
/root/gofourge/src/lab/cmd.go:13 +0x4f
==================
i is: 8212
i is: 54959831
i is: 109202117
我觉得不同的 goroutine 并发读写同一个变量,需要加锁,这应该是天经地义的常识。但是总有人以为,不加锁导致的问题最多就是读取的数据是修改前的数据,不能保证原子性罢了。是这样的吗?从上面的输出来看,似乎也差不多,其实这些都是典型的误解。
有些朋友可能不知道,在 Go(甚至是大部分语言)中,一条普通的赋值语句其实并不是一个原子操作(语言规范同样没有定义 `i++` 是原子操作, 任何变量的赋值都不是原子操作)。例如,在 32 位机器上写 int64 类型的变量是有中间状态的,它会被拆成两次写操作 MOV —— 写低 32 位和写高 32 位,如下图所示:
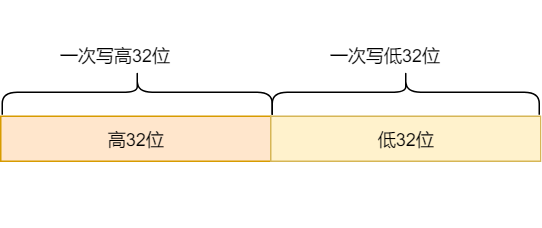
如果一个线程刚写完低 32 位,还没来得及写高 32 位时,另一个线程读取了这个变量,那它得到的就是一个毫无逻辑的中间变量,这很有可能使我们的程序出现诡异的 Bug。
而在 Go 的内存模型中,有 race 的 Go 程序的行为是未定义行为,理论上出现什么情况都是正常的。就拿上面的代码来说,当去掉 -race 参数执行时,大概率会得到这样的输出:
i is: 0
i is: 0
i is: 0
i is: 0
而用较老的 go 版本执行时,基本上执行一段时间,程序就会 HANG 住。所以讨论为什么出现这种现象实际上没有任何意义,不要依赖这种行为。
Mutex vs Atomic
解决 race 的问题时,无非就是上锁。可能很多人都听说过一个高逼格的词叫「无锁队列」。 都一听到加锁就觉得很 low,那无锁又是怎么一回事?其实就是利用 atomic 特性,那 atomic 会比 mutex 有什么好处呢?go race detector 的作者总结了这两者的一个区别:
Mutexes do no scale. Atomic loads do.
mutex 由操作系统实现,而 atomic 包中的原子操作则由底层硬件直接提供支持。在 CPU 实现的指令集里,有一些指令被封装进了 atomic 包,这些指令在执行的过程中是不允许中断(interrupt)的,因此原子操作可以在 lock-free 的情况下保证并发安全,并且它的性能也能做到随 CPU 个数的增多而线性扩展。
若实现相同的功能,后者通常会更有效率,并且更能利用计算机多核的优势。所以,以后当我们想并发安全的更新一些变量的时候,我们应该优先选择用 atomic 来实现。
参考资料
- The Go Memory Model
- Would this race condition be considered a bug?
- Benign Data Races: What Could Possibly Go Wrong?
- 理解Go标准库中的atomic.Value类型