Kong 从 0.11.0 版本开始节点之间的消息通信改为了数据库轮训机制(原先是通过 serf 实现的),通过最终一致性实现了节点的无状态,任何时候节点只需连上数据库即可工作。
当多个 Kong 节点连接到相同数据库时,便构建起了一个可以动态水平扩展的集群。Kong 通过其多级缓存 lua-resty-mlcache 和 worker 间事件通讯 lua-resty-worker-events 机制,来完成集群中各个节点的状态更新。
以下解析基于 Kong 0.12.3 版本。
1. 概述
实际上 Kong 出于性能上的考虑,并不会将每次请求都去查询数据库,而是将数据库中的实体缓存在了自身的多级缓存中。那么如何保证各个节点的缓存能够被及时刷新,这正是 Kong 集群要考虑的。也就是说 Kong 集群本质上就是对缓存的更新操作。
比如我们对 Kong 做了一个更改的请求,这个请求通常是通过 Admin API 这个路由处理的。也就是说最终执行数据库操作是在一个 Nginx worker 进程里。因为操作了数据库所以我们需要刷新这个 Kong 节点的所有 worker 的缓存,而且要把事件分发给其他 Kong 节点,让其他 Kong 节点刷新其所有 worker 的缓存。
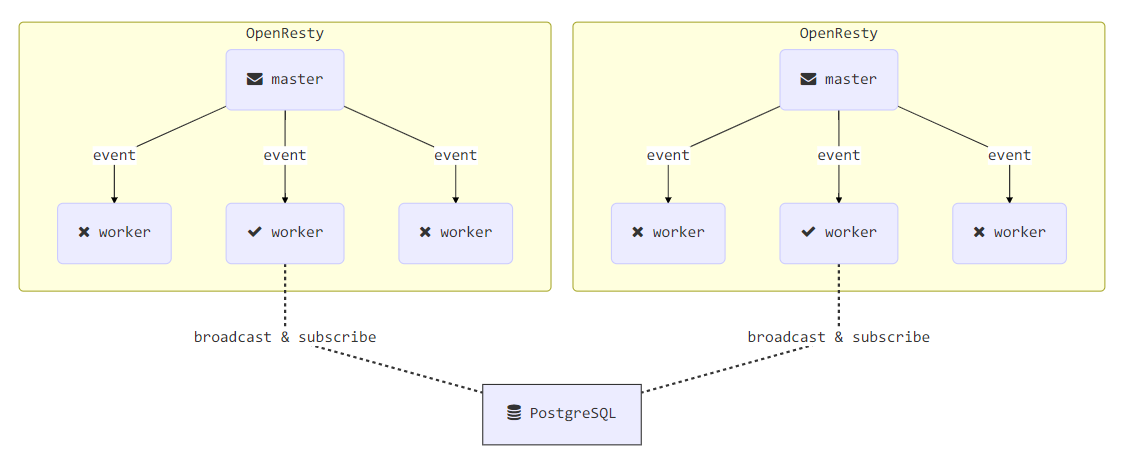
Kong 的缓存更新很多依赖于事件,而事件看起来相对比较复杂、也是比较有趣的一部分。其大致可以分为两类:
- worker 之间的事件,由 lua-resty-worker-events 来处理
- cluster 节点之间的事件,由 cluster_events.lua 来处理
这两类事件和缓存耦合的还是比较重的,Kong 也正是通过三者的协作来完成整个集群各个节点的缓存更新操作。
2. worker 事件
worker 事件采用的是事件监听模式。在 init_worker 阶段需要注册对应的回调函数,如:
worker_events.register(function(data)
-- ... 省略若干
local cache_key = dao[data.schema.table]:entity_cache_key(data.entity)
if cache_key then
cache:invalidate(cache_key)
end
-- ... 省略若干
end, "dao:crud")
当 worker 监听到事件后,就会触发这个回调。其中的关键就是 cache:invalidate(cache_key) 这个方法:
function _M:invalidate_local(key)
if type(key) ~= "string" then
return error("key must be a string")
end
log(DEBUG, "invalidating (local): '", key, "'")
local ok, err = self.mlcache:delete(key)
if not ok then
log(ERR, "failed to delete entity from node cache: ", err)
end
end
function _M:invalidate(key)
if type(key) ~= "string" then
return error("key must be a string")
end
self:invalidate_local(key)
local nbf
if self.propagation_delay > 0 then
nbf = ngx_now() + self.propagation_delay
end
log(DEBUG, "broadcasting (cluster) invalidation for key: '", key, "' ",
"with nbf: '", nbf or "none", "'")
local ok, err = self.cluster_events:broadcast("invalidations", key, nbf)
if not ok then
log(ERR, "failed to broadcast cached entity invalidation: ", err)
end
end
这个方法主要就是负责驱逐本地缓存并发送集群变更事件到数据库。那么问题来了,worker 的事件是怎么产生的呢?
答案就在 dao/dao.lua 里:
function DAO:insert(tbl, options)
-- ... 省略若干
local res, err = self.db:insert(self.table, self.schema, model, self.constraints, options)
if not err and not options.quiet then
if self.events then
local _, err = self.events.post_local("dao:crud", "create", {
schema = self.schema,
operation = "create",
entity = res,
})
if err then
ngx.log(ngx.ERR, "could not propagate CRUD operation: ", err)
end
end
end
return ret_error(self.db.name, res, err)
end
因为 Kong 所有的 API、Plugin 都是存储在数据库,所以事件的来源就是源于数据库的修改。可以看到 Kong 在 insert、update、delete 执行的时候都调用了 self.events.post_local 。这个方法就是给当前 worker 发送一条本地事件。该 worker 收到这个事件后,就开始驱逐对应的缓存并发送集群变更事件到数据库。
那么其他 worker 的缓存如何更新?其实这步是由 Kong 的缓存来完成,即 lua-resty-mlcache。mlcache 有个 IPC(就是 lua-resty-worker-events)来完成其他 worker 的更新。
3. cluster 事件
cluster 事件采用的是传统的发布订阅模式。事件的发布就是由上面提到的 worker 驱逐缓存的时候来完成。而事件的订阅则是在 init_worker 阶段 cache 的初始化时完成:
function _M.new(opts)
-- ... 省略若干
local ok, err = self.cluster_events:subscribe("invalidations", function(key)
log(DEBUG, "received invalidate event from cluster for key: '", key, "'")
self:invalidate_local(key)
end)
if not ok then
return nil, "failed to subscribe to invalidations cluster events " ..
"channel: " .. err
end
_init = true
return setmetatable(self, mt)
end
当 worker 收到事件后,就会驱逐本地缓存。同样由缓存的 IPC 负责完成其他 worker 的更新操作。
需要注意的是事件的订阅,本质上是基于 ngx.timer.at 的轮训机制。其还可以针对不同的 channel,各个 channel 实际上共享一个 timer 实现:
function _M:subscribe(channel, cb, start_polling)
-- ... 省略若干
if not self.callbacks[channel] then
self.callbacks[channel] = { cb }
insert(self.channels, channel)
else
insert(self.callbacks[channel], cb)
end
if start_polling == nil then
start_polling = true
end
if not self.polling and start_polling then
-- start recurring polling timer
local ok, err = timer_at(self.poll_interval, poll_handler, self)
if not ok then
return nil, "failed to start polling timer: " .. err
end
self.polling = true
end
return true
end
既然是轮训机制,那么就要保证一个节点中只要一个 worker 拉取数据库变更消息即可,以避免不必要的数据库压力。同样也要避免一个问题,就是上一次 poll 还未执行完成,下一次 poll 就不应该启动。Kong 这里使用了两把锁来处理这个问题:
local function get_lock(self)
local ok, err = self.shm:safe_add(POLL_RUNNING_LOCK_KEY, true,
max(self.poll_interval * 5, 10))
if not ok then
if err ~= "exists" then
log(ERR, "failed to acquire poll_running lock: ", err)
end
return false
end
if self.poll_interval > 0.001 then
ok, err = self.shm:safe_add(POLL_INTERVAL_LOCK_KEY, true,
self.poll_interval - 0.001)
if not ok then
if err ~= "exists" then
log(ERR, "failed to acquire poll_interval lock: ", err)
end
self.shm:delete(POLL_RUNNING_LOCK_KEY)
return false
end
end
return true
end
-
POLL_RUNNING_LOCK_KEYRUNNING_LOCK 可以保证同一时刻只有一个 worker 可以 poll 数据库改动;同时还能够保证上一次 poll 未完成时,下一轮 poll 则不会启动。并且一次 poll 执行的最长时间不能超过
max(poll_interval * 5, 10)。 -
POLL_INTERVAL_LOCK_KEYINTERVAL_LOCK 这个锁是用来保证不同 worker 之间不会发生
poll_interval偏移问题。例如,一个 worker 刚刚执行完成一轮 poll 后,另一个 worker 此时恰巧触发 poll 执行。那么从这个节点的角度来看,这个 poll 的poll_interval实际上是没有生效的,看起来就像是发生了偏移。而这个锁通过设置过期时间来解决这个问题。值得一提的是这个过期时间比
poll_interval的时间略小一点点,是因为poll_interval = poll + acquire lock,我猜测 Kong 这里是保守的考虑了抢锁的时间了。
轮训的主要逻辑由 poll() 来完成:
local function poll(self)
local min_at, err = self.shm:get(CURRENT_AT_KEY)
-- ... 省略若干
min_at = min_at - self.poll_offset - 0.001
local max_at = ngx_now()
log(DEBUG, "polling events from: ", min_at, " to: ", max_at)
for rows, err, page in self.strategy:select_interval(self.channels, min_at, max_at) do
if err then
return nil, "failed to retrieve events from DB: " .. err
end
if page == 1 then
local ok, err = self.shm:safe_set(CURRENT_AT_KEY, max_at)
if not ok then
return nil, "failed to set 'at' in shm: " .. err
end
end
-- ... 省略若干
end
return true
end
可以看到事件的轮训,是按照时间窗口查询的,这样可以保证每次 poll 驱逐的只是一部分缓存,从而有效的避免了 dog-pile 效应的产生。
还有一个问题,就是既然任何 Kong 节点都可以向数据库发送变更消息,那么将来这些过期的消息由谁来删除?
答案是数据库自己。查看 cluster_events 表的 DDL 可以看到:
kong=> \d cluster_events
Table "public.cluster_events"
Column | Type | Collation | Nullable | Default
-----------+--------------------------+-----------+----------+---------
id | uuid | | not null |
node_id | uuid | | not null |
at | timestamp with time zone | | not null |
nbf | timestamp with time zone | | |
expire_at | timestamp with time zone | | not null |
channel | text | | |
data | text | | |
Indexes:
"cluster_events_pkey" PRIMARY KEY, btree (id)
"idx_cluster_events_at" btree (at)
"idx_cluster_events_channel" btree (channel)
Triggers:
delete_expired_cluster_events_trigger AFTER INSERT ON cluster_events FOR EACH STATEMENT EXECUTE PROCEDURE delete_expired_cluster_events()
kong=>
当 insert 记录到这张表的时候,会触发一个 trigger,这个 trigger 会执行一个存储过程 delete_expired_cluster_events() 用来删除过期的事件:
CREATE OR REPLACE FUNCTION public.delete_expired_cluster_events()
RETURNS trigger
LANGUAGE plpgsql
AS $function$
BEGIN
DELETE FROM cluster_events WHERE expire_at <= NOW();
RETURN NEW;
END;
$function$
4. 缓存
Kong 基于 lua-resty-lrucache 和 lua_shared_dict 实现了自己的一套多级缓存机制:
┌─────────────────────────────────────────────────┐
│ Nginx │
│ ┌───────────┐ ┌───────────┐ ┌───────────┐ │
│ │worker │ │worker │ │worker │ │
│ L1 │ │ │ │ │ │ │
│ │ Lua cache │ │ Lua cache │ │ Lua cache │ │
│ └───────────┘ └───────────┘ └───────────┘ │
│ │ │ │ │
│ ▼ ▼ ▼ │
│ ┌───────────────────────────────────────┐ │
│ │ │ │
│ L2 │ lua_shared_dict │ │
│ │ │ │
│ └───────────────────────────────────────┘ │
│ │ │
│ ▼ │
│ ┌──────────────────┐ │
│ │ callback │ │
│ └────────┬─────────┘ │
└───────────────────────────┼─────────────────────┘
│
L3 │ I/O fetch
▼
Database, API, I/O...
-
L1
L1 级别缓存其实就是 lrucache,在 Lua VM 里,每个 worker 一份。由于 worker 是单进程方式存在,所以永远不会触发锁,效率更高。但是不同 worker 之间不共享,同一缓存数据会被冗余存储。
-
L2
L2 级别的缓存是 lua_shared_dict,同一个 Nginx 下只有一份,所有 worker 共享。由于使用的是共享内存,所以每次操作都是全局锁。如果高并发环境,不同 worker 之间容易引起竞争。
-
L3
L3 级别就是缓存未命中的情况,需要调用其他 callback 函数去获取数据然后缓存在 L2。为了避免 dog-pile 效应,这里使用 lua-resty-lock 来保证只有一个 worker 去查询数据库操作。
当请求到达时会首先去 L1 查询缓存,如果 miss 了接着再去 L2 查找,否则继续接着去查询 L3。上面提到的 Kong 的缓存驱逐其实就是将 L2 的缓存删除,并通过 IPC(就是 lua-resty-worker-events)来完成其他 worker 的更新。
需要注意的是 Kong 的缓存更新只是将缓存删除,实际上并未真正拉取数据库中的最新配置。拉取数据库中的最新配置由下一次请求完成。所以有时候你会发现,在对插件启用做了变更之后,API 的延时增加,其实这是个正常的行为,因为这个请求需要完成缓存的真正更新。
另外 Kong 默认将缓存的过期时间设置为 1 小时,来完成缓存的强制更新。如果你对 API 的延时要求比较高,可以在 Kong 的配置文件将参数 db_cache_ttl 置为 0 让缓存永不过期即可。